
Hunyuan Generation Generation工具Hunyuancustom表达了开放
作者:365bet网址 发布时间:2025-05-12 10:48
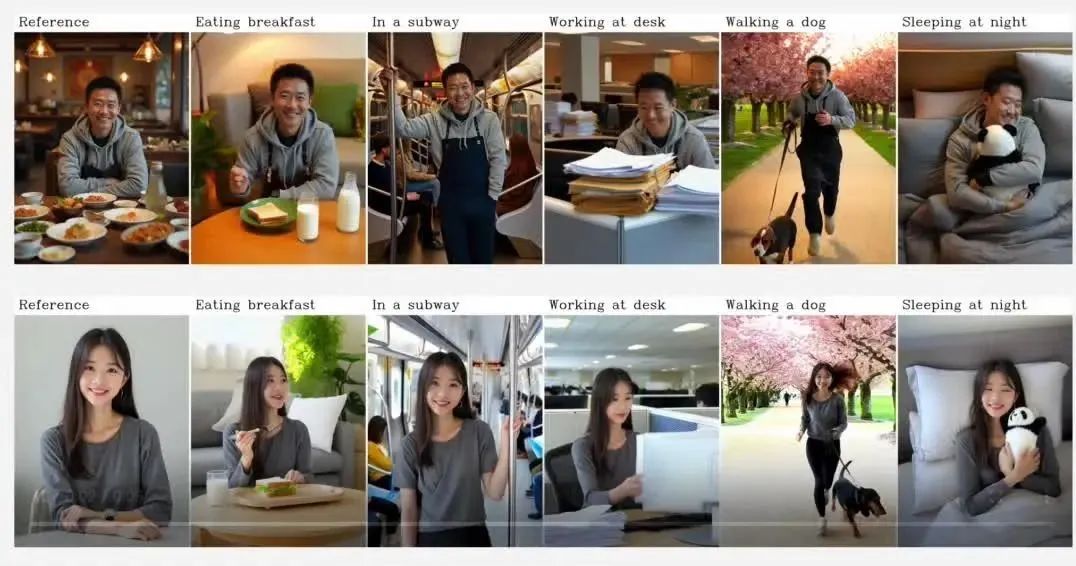 Hunyuan Generation Generation工具Hunyuancustom表达了开放的资源,即在文本,图像,音频和视频等视频中结合多模式输入的能力。
Hunyuan Generation Generation工具Hunyuancustom表达了开放的资源,即在文本,图像,音频和视频等视频中结合多模式输入的能力。
2025年5月9日11:48
在家
Home 5月9日报道说,Tencent Hunyuan今天宣布已正式推出并打开了一种新工具,该工具具有定制的视频一代Hunyuan Custom。该模型建立在Hunyuan视频生成模型(Hunyuan视频)上,同一主题的影响超过了现有的资源解决方案。据报道,Hunyuan Custom结合了制作多模式输入视频(例如文本,图像,音频和视频)的能力。这是一种具有高控制和高质量生成的智能视频创建工具。腾讯说,饥饿的自定义模型可以意识到S的功能Ingle-subsignitive视频一代,视频世代多主题,视频保护,本地视频编辑等。其中,单个主题一代的能力是在官方Hunyan网站上开放和启动的(官方网站上附加了IT家居:https://hunyyuan.tencent.com/)。用户可以在“模型Square-Tiusheng视频参考视频”中体验到这一点。其他功能在5月公开公开开放。在Hunyuancustom中,用户只需要上传目标人或事物的图片并提供文本描述(例如“他在狗walking狗”),而Hunyuancustom可以在图片中识别信息并在完全不同的动作,服装和场景中生成相互关联和自然的视频内容。除了单个主题外,此功能还可以实现多个对象视频的生成。用户提供了某人和某物的图片(例如一包薯片和一个人的图片)并进入t分机描述(例如“一个人毗邻游泳池,拿着薯片进行展示”),这可以使这两个主题根据需要出现在视频中。此外,Hunyuancustom不仅结合了图像和文本,而且具有强大的扩展功能。在音频驱动程序模式(单一主题)中,用户可以上传字符映像并匹配音频语音。该模型可以产生字符的影响,唱歌或执行其他场景中同一场景中的其他音频和视频的影响。它被广泛用于诸如数字实时广播,虚拟客户服务,教育演示等的场景中。在视频驱动程序模式下,HunyuSustom支持在任何视频剪辑,创造性的播种或场景中扩展角色或对象的自然替换或进入角色或对象,并且很容易实现重新构建视频和内容的重建视频和增强内容。以前,大多数视频生成模型都可以在文学和照片视频中实现视频。 Wensheng视频已经每次都会根据本文的直接单词进行修订,这很难保持角色和场景之间的一致性。一代图像视频模型主要实现“图片传输”。例如,Kuas您上传角色图片,最终生成的视频通常只在原始服装,姿势和照片场景中做出几个固定的表情或手势,而服装,背景和姿势几乎是不可能的。但是在某些场景中,创作者希望在保持相同角色的同时改变角色的环境和手势。视频发电的先前模型无法实现,多模式一代hunyustom的模型可以满足创作者的需求。通过引入身份增强机制和多模式融合模块,它真正意识到“图像给出了标识,文本定义了所有内容”。参考:经验门户:https://hunyuan.ntencent.com/modelsquare/home/play?modelid = 192项目官方网站:https://m.github.io/代码开放来源:https://github.com/tencent/hunyuancustom纸张纸:https://arxiv.org.org.org/pdf/2505.045122505.045122
Hunyuan Generation Generation工具Hunyuancustom表达了开放的资源,即在文本,图像,音频和视频等视频中结合多模式输入的能力。
Hunyuan Generation Generation工具Hunyuancustom表达了开放的资源,即在文本,图像,音频和视频等视频中结合多模式输入的能力。
2025年5月9日11:48
在家
Home 5月9日报道说,Tencent Hunyuan今天宣布已正式推出并打开了一种新工具,该工具具有定制的视频一代Hunyuan Custom。该模型建立在Hunyuan视频生成模型(Hunyuan视频)上,同一主题的影响超过了现有的资源解决方案。据报道,Hunyuan Custom结合了制作多模式输入视频(例如文本,图像,音频和视频)的能力。这是一种具有高控制和高质量生成的智能视频创建工具。腾讯说,饥饿的自定义模型可以意识到S的功能Ingle-subsignitive视频一代,视频世代多主题,视频保护,本地视频编辑等。其中,单个主题一代的能力是在官方Hunyan网站上开放和启动的(官方网站上附加了IT家居:https://hunyyuan.tencent.com/)。用户可以在“模型Square-Tiusheng视频参考视频”中体验到这一点。其他功能在5月公开公开开放。在Hunyuancustom中,用户只需要上传目标人或事物的图片并提供文本描述(例如“他在狗walking狗”),而Hunyuancustom可以在图片中识别信息并在完全不同的动作,服装和场景中生成相互关联和自然的视频内容。除了单个主题外,此功能还可以实现多个对象视频的生成。用户提供了某人和某物的图片(例如一包薯片和一个人的图片)并进入t分机描述(例如“一个人毗邻游泳池,拿着薯片进行展示”),这可以使这两个主题根据需要出现在视频中。此外,Hunyuancustom不仅结合了图像和文本,而且具有强大的扩展功能。在音频驱动程序模式(单一主题)中,用户可以上传字符映像并匹配音频语音。该模型可以产生字符的影响,唱歌或执行其他场景中同一场景中的其他音频和视频的影响。它被广泛用于诸如数字实时广播,虚拟客户服务,教育演示等的场景中。在视频驱动程序模式下,HunyuSustom支持在任何视频剪辑,创造性的播种或场景中扩展角色或对象的自然替换或进入角色或对象,并且很容易实现重新构建视频和内容的重建视频和增强内容。以前,大多数视频生成模型都可以在文学和照片视频中实现视频。 Wensheng视频已经每次都会根据本文的直接单词进行修订,这很难保持角色和场景之间的一致性。一代图像视频模型主要实现“图片传输”。例如,Kuas您上传角色图片,最终生成的视频通常只在原始服装,姿势和照片场景中做出几个固定的表情或手势,而服装,背景和姿势几乎是不可能的。但是在某些场景中,创作者希望在保持相同角色的同时改变角色的环境和手势。视频发电的先前模型无法实现,多模式一代hunyustom的模型可以满足创作者的需求。通过引入身份增强机制和多模式融合模块,它真正意识到“图像给出了标识,文本定义了所有内容”。参考:经验门户:https://hunyuan.ntencent.com/modelsquare/home/play?modelid = 192项目官方网站:https://m.github.io/代码开放来源:https://github.com/tencent/hunyuancustom纸张纸:https://arxiv.org.org.org/pdf/2505.045122505.045122 下一篇:没有了